Building an end-to-end Visual Q&A System using State of the Art Multi-Modal Models on Databricks
In the previous post, we dove into the emerging landscape of AI assistance in retail, highlighting the transformative potential of LLaVa. Building on this momentum, we now embark on a journey to harness the power of cutting-edge AI for a specific, groundbreaking application: creating an end-to-end Visual Q&A System. This blog will guide you through the intricacies of leveraging state-of-the-art models (such as LLaVa or LLaVa-NeXT) within a flexible platform like Databricks, aiming to provide an insightful, hands-on tutorial. From trying out the model, to developing the MLflow artifact, to model deployment, we’ll navigate the complexities of this innovative application smoothly, equipping you with the knowledge to transform visual data into actionable insights. I’m deliberately going to maintain a super-casual tone to the blog, so if you’re someone who cares too much about pedantic lingo, apologies. Otherwise, let’s get started!
Soon after I posted the previous blog, I noticed the following release was pushed out on the main transformers library by the awesome team at huggingface! It promised a new release and an interesting model addition that’s right in the spot for us — LLaVa-NeXT (LLaVa v1.6)


Clearly, this model is a significant step-up from LLaVa v1.5, and it comes in four different flavors, depending on the choice of the LLM used. If you care about ultimate quality, you can go with Hermes-Yi-34B but, for our purposes, let’s choose Mistral-7B.

The interesting thing here is, the research team also publish benchmarks against popular proprietary models like GPT4-V and the Gemini models. What’s really interesting to see is that these models are actually quite competitive with Gemini Pro! While that’s impressive, I’ve noticed that models in the wild and the experience with them can vary depending on the model, so you’ve got to take anything you see around benchmarks with a pinch of salt. That being said, the results in general are quite impressive!

Ok, to get the model working on Databricks Notebooks, all you have to do is make sure you upgrade transformers to version 4.39.0 and then, its dead simple — just use the transformers api! Shown below is the example from the docs.
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
from PIL import Image
import requests
from rich import print
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
model = LlavaNextForConditionalGeneration.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", torch_dtype=torch.float16, low_cpu_mem_usage=True)
model.to("cuda:0")
# prepare image and text prompt, using the appropriate prompt template
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "[INST] <image>\nWhat is shown in this image? Keep it brief[/INST]"
inputs = processor(prompt, image, return_tensors="pt").to("cuda:0")
# autoregressively complete prompt
output = model.generate(**inputs, max_new_tokens=100)
result = processor.decode(output[0], skip_special_tokens=True)You can simply run this on a notebook! See below how what this sample image contains and what the model predicted. Not bad for a 7b model!
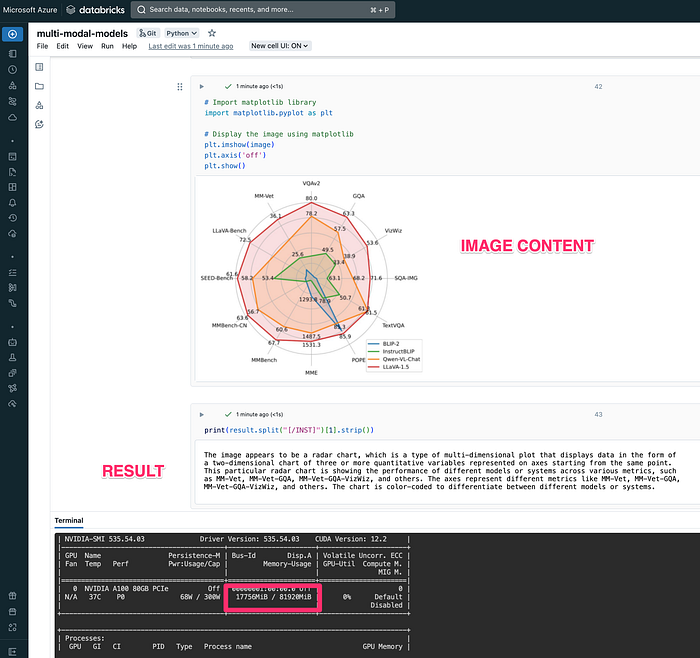
Ok, that’s good. But, we need to get the model ready for serving via Databricks Model Serving. On Databricks, this is easily done by packaging the model as an MLflow model.
from huggingface_hub import snapshot_download
import mlflow.pyfunc
import mlflow
import requests
import pandas as pd
import base64
import io
from PIL import Image
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import base64
snapshot_location = snapshot_download(repo_id="llava-hf/llava-v1.6-mistral-7b-hf")
class LlavaNext7bMistral(mlflow.pyfunc.PythonModel):
def load_context(self, context):
"""Method to initialize the model and processor."""
self.model = LlavaNextForConditionalGeneration.from_pretrained(
context.artifacts['repository'],device_map="auto",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
)
self.processor = LlavaNextProcessor.from_pretrained(context.artifacts['repository'], device_map="auto")
self.model.eval()
def _generate_response(self, usr_prompt, image):
"""
This method generates prediction for a single input.
"""
# Build the prompt
# Send to model and generate a response
inputs = self.processor(text=usr_prompt, images=image, return_tensors="pt").to(device="cuda")
output = self.model.generate(
**inputs,
max_new_tokens=200,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id
)
result = self.processor.batch_decode(output, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
return result
def predict(self, context, model_input):
"""Method to generate predictions for the given input."""
outputs = []
for i in range(len(model_input)):
usr_prompt = model_input["prompt"][i]
image = model_input["image"][i]
# decode and read the image
decoded_image = base64.b64decode(image)
image = Image.open(io.BytesIO(decoded_image))
generated_data = self._generate_response(usr_prompt,image)
outputs.append(generated_data)
return {"candidates": outputs}
# Define input and output schema for the model
from mlflow.models.signature import ModelSignature
from mlflow.types import DataType, Schema, ColSpec
input_schema = Schema([ColSpec(DataType.string, "prompt"), ColSpec(DataType.string, "image")])
output_schema = Schema([ColSpec(DataType.string)])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# Define input example
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
response = requests.get(url)
image = response.content
encoded_image = base64.b64encode(image).decode("ascii")
input_example = pd.DataFrame({
"prompt":["<image>\nUSER: What's the content of the image?\nASSISTANT:"],
"image":[encoded_image]
})Packaging the model like this will allow us to simply log the model into MLflow and then you can register this model to Unity Catalog.
with mlflow.start_run() as run:
mlflow.pyfunc.log_model(
"model",
python_model=LlavaNext7bMistral(),
artifacts={'repository' : snapshot_location},
input_example=input_example,
pip_requirements=["torch==2.0.1","transformers==4.39.0", "cloudpickle==2.0.0","accelerate==0.25.0","torchvision==0.15.2","optimum==1.18.0"],
signature=signature
)Once the model is in Unity Catalog, we can simply serve the model as an endpoint via Databricks Mosaic AI Model Serving. But, this isn’t the entire story. This is a minor operational detail as our endeavor is to build an application that takes advantage of this API, which would then allow us to investigate many more multi-modal use cases live (in addition to what we already explored here). So, let’s keep going! Also, you can find all the code needed to replicate all of this here.
This isn’t everything. In the interest of exploring these use cases, let’s build out a simple web app. Instead of using the regular options (chainlit, gradio, streamlit etc.) that everyone knows about, I tried to use this opportunity to explore nicegui. Two reasons why I wanted to try it out. This. And the fact that it rhymes with nice guy. The app’s called Detectocat (thank you ChatGPT) for obvious reasons. It follows 2 cardinal rules: Any app that helps a user meaningfully should have an animal’s name on it AND it should be confounding enough to intrigue users. So, there’s that. The code for the app itself is here. The point of the rest of the blog is to highlight opportunities that lie in this space and not get too embroiled in the niceguiapp building specifics. Overall, I felt it offered a quick and an easy option to build simple applications. Took me half a day to go through the docs and build out the app. We’re going to use it to explore a variety of use cases. So, let’s get started.
Here’s how the app works. a. You provide an image b. You give it a question. As soon as the image uploads, the app hits the Model Serving endpoint which runs LLaVa-NeXT and the response it provides is based on the content of the image provided. Let’s try this on a few use cases.
1. Assistive Q&A based on an image
This is the 101 explain the image use case. We can simply have images be explained by our bot. This can be relevant to improve assistive features of a product or simply add additional information to hydrate the backend analytics around specific products. Here’s an example of how this could work. For this one, let’s use an AI generated image.
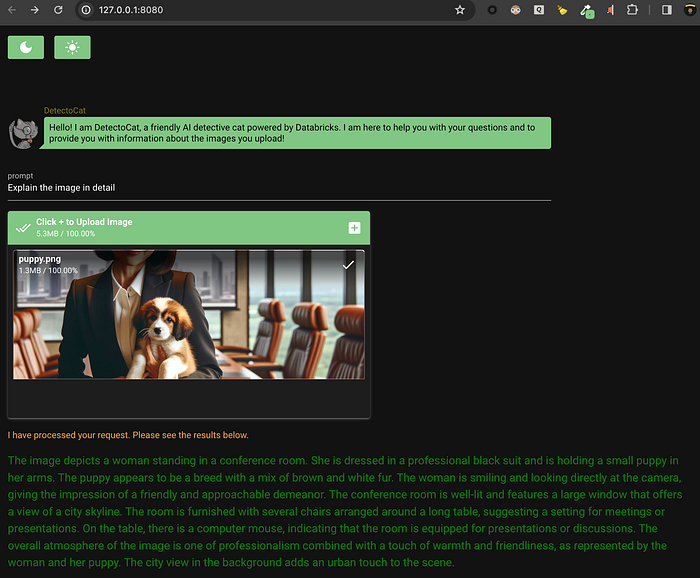
2. Extract properties of interest from a web page
This could really allow companies take advantage of the internet and scale competitive analysis to the next level. See below for an example where I ask the bot about the product name and the description. The opportunities are endless just in this space.
3. Hyper-Personalization
Wouldn’t it be good if we had a way to learn from user behavior and adapted the experience based on it? What if there was a way to see where in a given visit a user spent most of their time and use that as a way to “establish communication” with the user on some other channel? That would require that we not just understand what the user was looking at, but also to be able to convert that into actionable insight in real-time, so when they bounce post the visit, you could offer them meaningful starting points for re-engagement. This would require us to understand the content of the assets on a specific page (such as a hero image) on an on-going basis and then establish hyper personalization strategies based on it. This way, its not about which segment a user falls into. It’s truly about them. Shown below is an example of LLaVa-NeXT doing just this, powered by Databricks.
4. Generating chart summaries or asking pointed Q&A.
This one is quite interesting. I’m still not super sold on this idea but it's something worth exploring because the model seems to demonstrate good reasoning and performs decent on OCR as well. This area might require further refinement. But it does provide yet another avenue to explore in addition to what llama-index provides via deplot. See below — an example of how this would work.

5. Bot assisted Visual Inspection for Condition Monitoring
Finally, a multi-modal bot can be used to analyze the visual content automatically and alert the user based on its content. Imagine a situation where you have a companion app, where in the app you log your food (this is not an uncommon situation as we know) but when you do this, if the bot understands the user specific preferences (such as a specific user being allergic to nuts for e.g.), it can automatically intervene and help the user course-correct and make a better choice. See below, an example of where the bot is doing exactly this. Obviously, this is just an extremely simplified example, but similar parallels could be drawn in many settings. The possibilities of creating such meaningful experiences with consumer facing tech products are endless.
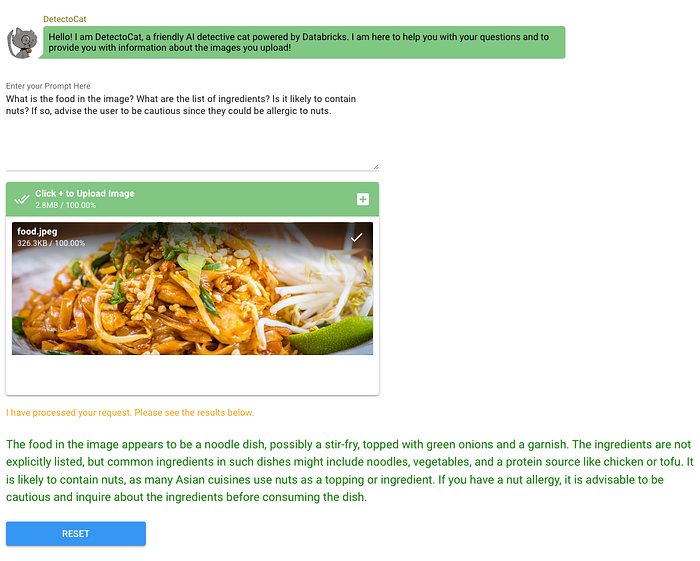
This wraps up our exploration of LLaVa-NeXT. We looked at how it does generally on broad benchmarks, how it can be easily deployed on Databricks and finally demonstrated how several use cases can be delivered via a web app, where the app allowed us to interact with the model hosted as an endpoint on Databricks. Hopefully, this was fun for you to read and manages to inspire you into trying your own use case! That’s it for now! Enjoy!
If you thought this was valuable or you want to connect with me, please reach out to me on LinkedIn
