Fine-Tuning and Deploying of LLMs : PEFT and GPTQ! Part 2/2
What if we start from a quantized model?
If you’re interested in taking a base Large Language model (LLM) and fine-tuning it using QLoRA and then quantizing your model for serving, check out Part1. Instead, if you want to start from a GPTQ quantized model such as the llama-2–7b-gptq, and fine-tune it using LoRA, read on.
GPTQ is a post training quantization technique that adopts a mixed int4/fp16 quantization scheme where weights are quantized as int4 while activations remain in float16. During inference, weights (not activations) are dequantized on the fly and the actual compute is performed in float16. There’s some nuance in how and where the dequantization process happens and how it saves GPU memory and communication bandwidth. The authors of the paper talk in depth about this, but in short and I quote from the paper’s summary section:
“GPTQ, is an approximate second-order method for quantizing truly large language models. GPTQ can accurately compress some of the largest publicly-available models down to 3 and 4 bits, which leads to significant usability improvements, and to end-to-end speedups, at low accuracy loss.”
This sounds great! However, what happens when you have to now fine-tune this “previously quantized” model? This is where training with peft helps. As seen in the recent past, pretty much any useful open source model has been shared publicly by the “TheBloke” in useful formats such as gptq, ggml etc.
So, with that in mind, lets start with the same dataset we used for the previous blog — the dialogsum chat summarization dataset. This way, the pre-processing is the same and we can take the HuggingFace integration with GPTQ via the optimum api for a spin. Also, everything I talk about here was done on a RTX A6000 GPU. Once the dataset is loaded and prepared for the training exercise, we can quickly download the llama2 GPTQ model as shown below.
from datasets import Dataset
dataset = Dataset.from_pandas(train_df)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import prepare_model_for_kbit_training
from transformers import GPTQConfig
model_id = "TheBloke/Llama-2-7B-GPTQ"
quantization_config_loading = GPTQConfig(bits=4, disable_exllama=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config_loading,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.config.use_cache = False
# https://github.com/huggingface/transformers/pull/24906
#disable tensor parallelism
model.config.pretraining_tp = 1This step usually takes a couple of minutes to download the model and the tokenizer. At the time of this writing, training with exllama is unstable. Therefore, we have to pass the GPTQConfig to modify the downloaded model’s config to disable it. Next, to train this model using peft we can prep the model adapter config and attach it to the model.
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["k_proj","o_proj","q_proj","v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)We can now define the TrainingArguments and then instantiate the trainer to train the model.
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
args=TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=300,
learning_rate=2e-4,
fp16=True, #use mixed precision training
logging_steps=1,
output_dir="outputs_gptq_training",
optim="adamw_hf",
save_strategy="epoch")
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset,
peft_config=config,
dataset_text_field="text",
tokenizer=tokenizer,
packing=False,
max_seq_length=512)
trainer.train()At this point, we can see that the model while being trained on the GPU only consumes ~6.5GB of GPU memory! (as compared to the base meta/llama-2-7b model which consumes 26.5 GB of GPU memory). This is great and is likely similar if one were to use QLoRA as well.

The rest of it remains the same as Part-1. Now post training, the model can be persisted to disk. However, at this time one can’t merge the LoRA adapter with the quantized model we started with. This is fine as long as we can simply load the model back from disk as needed and be used for inference, which we can certainly do as shown here.
from peft import AutoPeftModelForCausalLM
from time import perf_counter
from rich import print
from transformers import GenerationConfig
# To perform inference on the test dataset example load the model from the checkpoint
persisted_model = AutoPeftModelForCausalLM.from_pretrained(
output_dir,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="cuda")
# Some gen config knobs
generation_config = GenerationConfig(
penalty_alpha=0.6,
do_sample = True,
top_k=5,
temperature=0.5,
repetition_penalty=1.2,
max_new_tokens=100
)
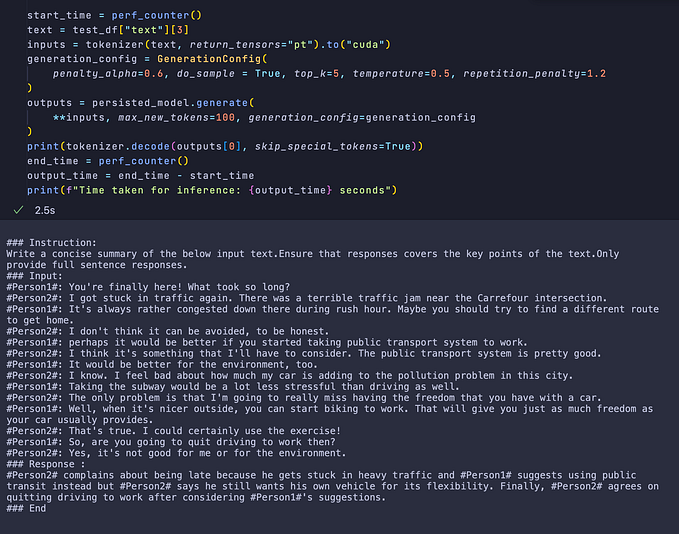
start_time = perf_counter()
outputs = persisted_model.generate(**inputs, generation_config=generation_config)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
end_time = perf_counter()
output_time = end_time - start_time
print(f"Time taken for inference: {round(output_time,2)} seconds")The output seems to be of a decently good quality, although it is slightly slower (~ 3.2s) than running it directly on the quantized model as we did in Part-1.
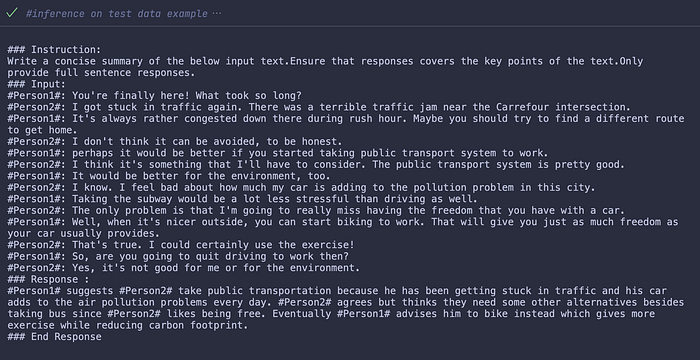
This completes our series of blogs exploring useful strategies for LLM fine tuning such as LoRA QLoRA and GPTQ for post training quantization.
To connect with me, please reach out to me on LinkedIn